
Quality Growth
Global equities specialists since 1984. We provide a boutique investment experience for institutional and intermediary clients around the world.
After such a powerful run in AI-related semiconductor spending, it is natural to focus on when the next correction might occur. While that debate matters, we believe the more important question is different: Has the industry moved beyond a short-lived spike in AI enthusiasm and into a period of structurally higher demand for accelerated computing? We believe it has.
Semiconductors remain a cyclical industry, and after growth of this magnitude, some moderation would be neither surprising nor unhealthy. Yet evidence across the semiconductor value chain continues to support durable demand through 2026 and into 2027.
What sets this cycle apart from prior ones is visibility. What was once a 6–12-month debate around inventory and pricing has extended to something closer to 24 months. This reflects the growing complexity of chip manufacturing, longer production timelines for the most advanced tools, and the strategic way large cloud companies now plan their infrastructure investments years in advance. That degree of visibility is rare for this industry and is a distinction that meaningfully informs how we think about portfolio positioning.
We are not arguing that the cycle has been abolished. Our point is narrower: the mid-term visibility window has meaningfully extended. The economics of the buildout may work well for the “picks-and-shovels” companies that supply essential tools and components, regardless of whether hyperscalers see a clear improvement in their ROIC.
In our view, companies with measurable returns, durable competitive moats, and solid economics should benefit regardless of which model, hyperscaler, or foundation lab ultimately wins. The bottlenecks remain concentrated in a small number of hard-to-replicate areas: advanced chip manufacturing, packaging, memory, networking, and power. As such, chips tied to computing, memory and power, along with the equipment used to manufacture them, remain the clearest expressions of this view in our portfolios.
Our investment process is bottom-up, and for a theme as crowded and fast-moving as AI infrastructure, there is no substitute for being physically present in the supply chain. Over the past 18 months, we have spent time with management teams, engineers, and operators across the accelerated computing stack — from Broadcom in Silicon Valley to Taiwan Semiconductor Manufacturing Company (TSMC)’s manufacturing facilities in Taiwan and Arizona, and to key equipment players in Europe and Japan. The message has been consistent: End demand for AI compute appears to remain resilient, not only through 2026 but likely into 2027 and, absent an exogenous shock, remains structural, in our view, for the multi-year horizon.
Twelve months ago, a reasonable bear case on AI spending rested on three pillars: first, that hyperscaler capex was front-loaded and would digest in 2026–27; second, that training compute would saturate as model scaling hit diminishing returns; and third, that enterprise adoption would lag, leaving infrastructure underused. In our view, each of these concerns has weakened.
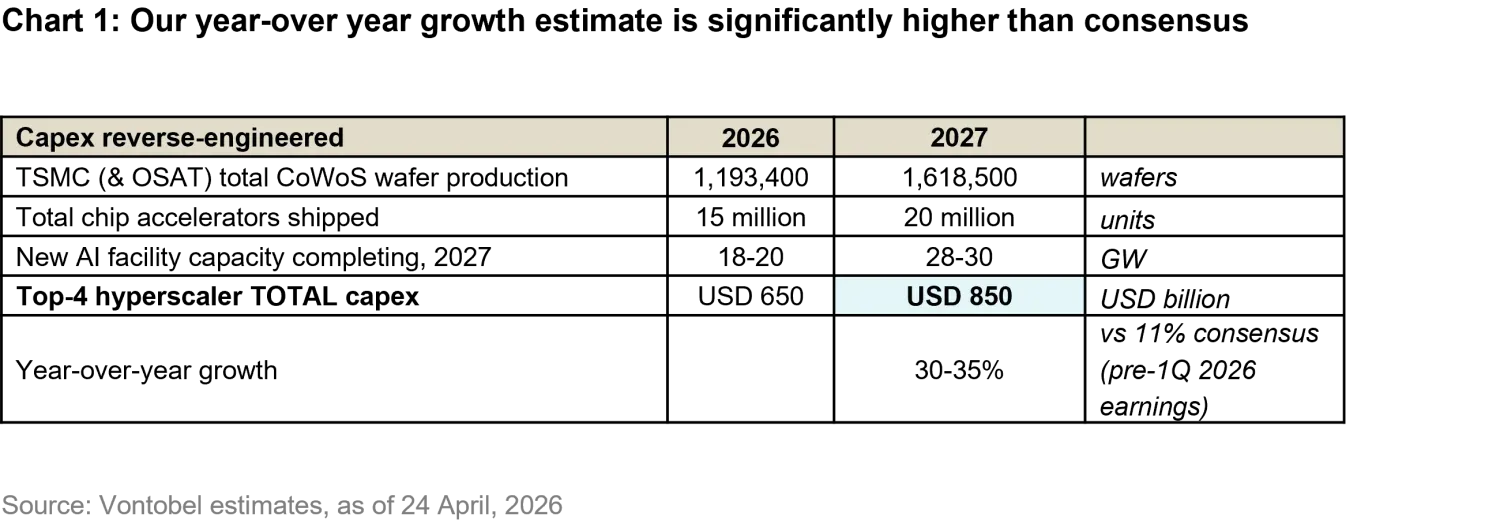
Starting from advanced packaging capacity and assuming industry output of roughly 18-20 million AI accelerator chips, we estimate the resulting deployed computing capacity by applying an average density of roughly 500,000 chips per gigawatt of data center power. This translates into approximately 28-30 gigawatts of incremental capacity.
Applying an all-in build cost of roughly USD 35-40 billion per gigawatt suggests that total global AI infrastructure spend may approach the low-trillion-dollar range. The Big Four hyperscalers account for roughly 70-75% of that total, which implies USD 850 billion of spending in 2027. That figure represents roughly 30% growth year-over-year versus 2026 guidance, and, importantly, is materially above the 11% growth embedded in consensus estimates only a few weeks ago (pre-1Q 2026 earnings results).
The obvious question, and the one our clients ask most, is: Will hyperscaler spending at these levels earn an adequate return? The simple answer is that near-term accounting returns remain weak.
The snapshot still looks weak. Cumulative total capex across the Big Four from 2024–2027 is likely to approach USD 2 trillion, with AI infrastructure representing the dominant, but not precisely disclosed, share. Direct AI revenue disclosures remain uneven: Microsoft has disclosed an AI annualized revenue run-rate of roughly USD 37 billion, AWS AI is above USD 15 billion, and Google Cloud’s recent growth and backlog point to strong AI-driven demand, although not all of that revenue is separately disclosed as AI. Our working estimate is that 2027 AI-related revenue reaches roughly USD 185–240 billion, depending on how broadly one includes ad, search and workflow uplift. At a blended 55% gross margin, that revenue is still unlikely to fully absorb the depreciation and operating costs of such a rapidly expanding asset base. On a one-year accounting basis, AI ROIC therefore remains weak, even if lifecycle returns are more constructive.
Lifecycle returns are more constructive. Older chips do not suddenly become worthless when their accounting depreciation period ends. They can be redeployed into simpler AI tasks at a much lower incremental cost, generating a meaningful tail of cash flow. Google has disclosed that seven to eight -year-old Tensor Processing Units (TPUs) still operate at near-100% utilization. This “tail effect” materially lifts lifecycle returns.
On a per-gigawatt basis, we estimate lifecycle internal rates of return (IRR) in the mid-to-high teens for hyperscaler internal workloads and in the low-to-mid teens for capacity sold through third-party cloud contracts. These returns are constructive, if not spectacular, and well above what the snapshot ROIC implies. The accounting return in any given year does not capture the true economics. A useful analogy is a toll road: measured only in the year it is built, it appears to be a poor investment, but its economics make sense when evaluated across decades of usage.
The key question is not whether marginal ROIC improves, but whether it improves fast enough to offset the continuous reinvestment required to remain at the frontier.
But this is not our thesis. The semiconductor value chain earns its own ROIC upfront, completely insulated from when – or whether – hyperscaler AI economics officially inflect positive on an accounting basis. A single company produces the EUV lithography tools required for leading-edge logic. A single foundry produces essentially all of the world’s leading-edge AI accelerators. A handful of companies supply the advanced packaging, the high-bandwidth memory, inspection, the dicing equipment, and the custom silicon design IP. As investors, we do not need to predict which companies will win at the application layer in order for chip manufacturers to be successful.
Our preference is for companies that:
Broadcom sits at two of the most attractive nodes in the stack. Its custom accelerator (XPU) franchise is winning designs with multiple hyperscalers seeking to diversify away from a single-vendor accelerator stack, and the company has recently disclosed a long-term agreement with Google extending through 2031. This strategic positioning was reinforced at Google’s Cloud Next event in April 2026, where the eighth-generation TPU – split for the first time into separate training and inference chips and developed in partnership with Broadcom – underscored the strategic, multi-year nature of the relationship.
Broadcom’s networking chips, such as Tomahawk, Jericho, the optical roadmap, are effectively non-substitutable at the scale-out fabric layer that every large AI cluster depends on. These systems handle the movement of data between thousands of chips, and there are few viable alternatives at this scale. We expect custom XPUs to capture a meaningfully larger share of the total AI compute chip market over the coming decade. Broadcom exhibits predictable free cash flow, long-standing customer relationships, and a strong pipeline for custom silicon.
Semiconductor capital equipment. AI demand is not only increasing the number of advanced chips being produced; it is also increasing the complexity of how they are made. Leading-edge logic chips, high-bandwidth memory (HBM), advanced packaging, backside power delivery, and tighter yield requirements all raise the value of the manufacturing tool chain. Companies such as ASML, KLA, Tokyo Electron, Disco, and their peers are the purest structural expression of this trend. ASML stands out in particular, supported by two largely independent growth drivers: expanding EUV tool volumes as leading-edge processes mature, and the ramp of next-generation High-NA systems for the sub-2nm production. These equipment suppliers, often operating in monopolies and duopolies, function as the ultimate toll collectors on the road to advanced computing.
TSMC remains at the center of this ecosystem. Its Arizona investment project underscores how far the industry has moved away from short-term demand swings to long-term strategic decisions about capacity placement and multi-year platform planning. TSMC’s 2026 Technology Symposium in April reinforced this: TSMC debuted A13, discussed A122 as a 2029 production technology, and outlined larger CoWoS packages, including 14-reticle CoWoS planned for 2028 and larger versions thereafter. This includes larger CoWoS packages designed to place more computing power and memory into a single system.
The first Arizona facility began high-volume N4 production in late 2024. The second is targeted to ramp N3 in the second half of 2027, while the third is intended for N2 and A16 later in the decade. These timelines are not the milestones of a fleeting demand pulse. During our site tour of TSMC’s Arizona facility in April, we were impressed by the scale and speed of the construction process.
In 2023, we published an article highlighting TSMC and how its role as a versatile chipmaker underpins its potential for steady, industry-wide gains, independent of any single company's success in AI.
A note on valuation: We remain disciplined on entry points even where the structural thesis is strong. In an environment where many AI-exposed stocks have re-rated significantly, position sizing and valuation awareness matter as much as thematic conviction. We have trimmed positions where we believe risk-reward has become less compelling and added where price dislocations have created opportunities.
After three years of extraordinary growth, a moderation or temporary correction in 2028 remains possible if utilization disappoints or if macro liquidity tightens. Hence, a genuine air-pocket in hyperscaler capex, driven either by disappointing ROIC or by a coordinated pause, would compress equipment and substrate orders quickly.
Another potential risk is that an algorithmic breakthrough that materially reduces the compute required per unit of model capability would lengthen the useful life of installed silicon and push out the replacement cycle. We believe this scenario is more likely than the market appears to be pricing in. Other factors to watch include the bifurcation of the supply chain due to geopolitical tensions. After a buildout of this magnitude, we believe a straightforward inventory correction is not a tail risk at all – it is a base-case feature of semiconductor cycles, and one we expect to navigate at some point in the next 18 to 30 months.
We monitor a specific set of leading indicators: order coverage at the leading foundry, advanced packaging utilization, hyperscaler capex guidance deltas, equipment book-to-bill, token pricing and inference gross margins, the trajectory of hyperscaler cash flows, and the pace of custom-silicon design wins. We adjusted positioning more than once in the past two years when those signals have moved, and if any of them move meaningfully against the thesis, we will adjust again.
Our first article on semiconductors, A Coming of Age Story, was published in 2021, where we conclude that the industry is characterized by long-term secular tailwinds. Today, our view remains consistent: the buildout of AI computing infrastructure is not a story that ends in 2026.
Demand has broadened from training new models to reasoning inference, and the monetization model is shifting from GPU rentals to per-token usage.
The most important bottlenecks in the supply chain, in our view, are concentrated in a small number of companies that have built durable competitive advantages over decades. The cycle has not been repealed, and we should expect moderation at some point. But the long-term trajectory of accelerated computing appears structural.
Evidence from the field keeps us constructive, and we continue to favor the picks-and-shovels providers whose economics are measurable and whose returns do not depend on picking the winner above them.
1. Throughout this article, the "Big Four" refers to the four large US AI infrastructure buyers: Microsoft, Amazon, Alphabet and Meta. Not all are third-party cloud providers, but all are central to the AI infrastructure cycle.
2. TSMC’s A13 and A12 are next-generation, sub-2nm semiconductor fabrication processes slated for volume production in 2029. They represent an extension of TSMC's "A" node family, designed to power next-generation AI accelerators, high-performance computing (HPC) servers, and premium consumer devices.
Important Information: References to portfolio holdings and other companies are for illustrative purposes only as of the date of publication to elaborate on the subject matter under discussion. Information provided should not be considered research or a recommendation to purchase, hold, or sell any security nor should any assumption be made as to the present or future profitability or performance of any company identified or security associated with them. There is no assurance that any securities discussed herein will remain in the portfolio at the time you receive this communication, or that securities sold have not been repurchased. Securities discussed may represent only a certain percentage of a portfolio’s holdings. Refer to the “Related Strategies/Funds” for further evaluation. Any projections or forward-looking statements regarding future events or the financial performance of countries, markets and/or investments are based on a variety of estimates and assumptions. Such information should not be regarded as an indication that Vontobel considers these forecasts to be reliable predictors of future events and they should not be relied upon as such. Actual events or results may differ materially and, as such, undue reliance should not be placed on such forward-looking information.






