2026 Large Language Models Outlook
Multi Asset Boutique
Introduction
After a period of rapid experimentation and scale-up, large language models (LLMs) have entered a more mature phase in which differentiation, reliability, and real-world deployments are becoming as important as raw model performance. We examine how the competitive landscape remains open: there is no single winner in the AI race, and multiple technical and commercial strategies will continue to coexist. At the same time, leading model providers are increasingly specializing, with architectures tailored to specific use cases rather than general-purpose dominance. This analysis explores the contrasting approaches of open versus closed model offerings, assesses how regulation will shape AI development across the world’s three major economic powers, and considers China’s growing significance in research and its potential to emerge as a long-term contender. Finally, we conclude with forward-looking insights and key predictions for artificial intelligence in 2026. We chose to title this analysis LLM Outlook rather than AI Outlook because these terms are often treated as interchangeable, when they are not. AI encompasses a much broader range of models and technologies, while LLMs represent only a specific, currently popular, subset of the field.
There is still no clear winner
Despite the rapid progress in foundation language models, we believe no single provider can yet be considered the undisputed victor. When OpenAI first launched their GPT model, the game seemed over for at least 6 months, until Google was able to provide a competing alternative. Over the past few years, leadership has shifted repeatedly among multiple players, reflecting both the fast pace of innovation and the narrow performance gaps that separate the most advanced models. As shown in Figure 1, the latest round of evaluations places Google’s Gemini 3 Pro at the top of current benchmarks.
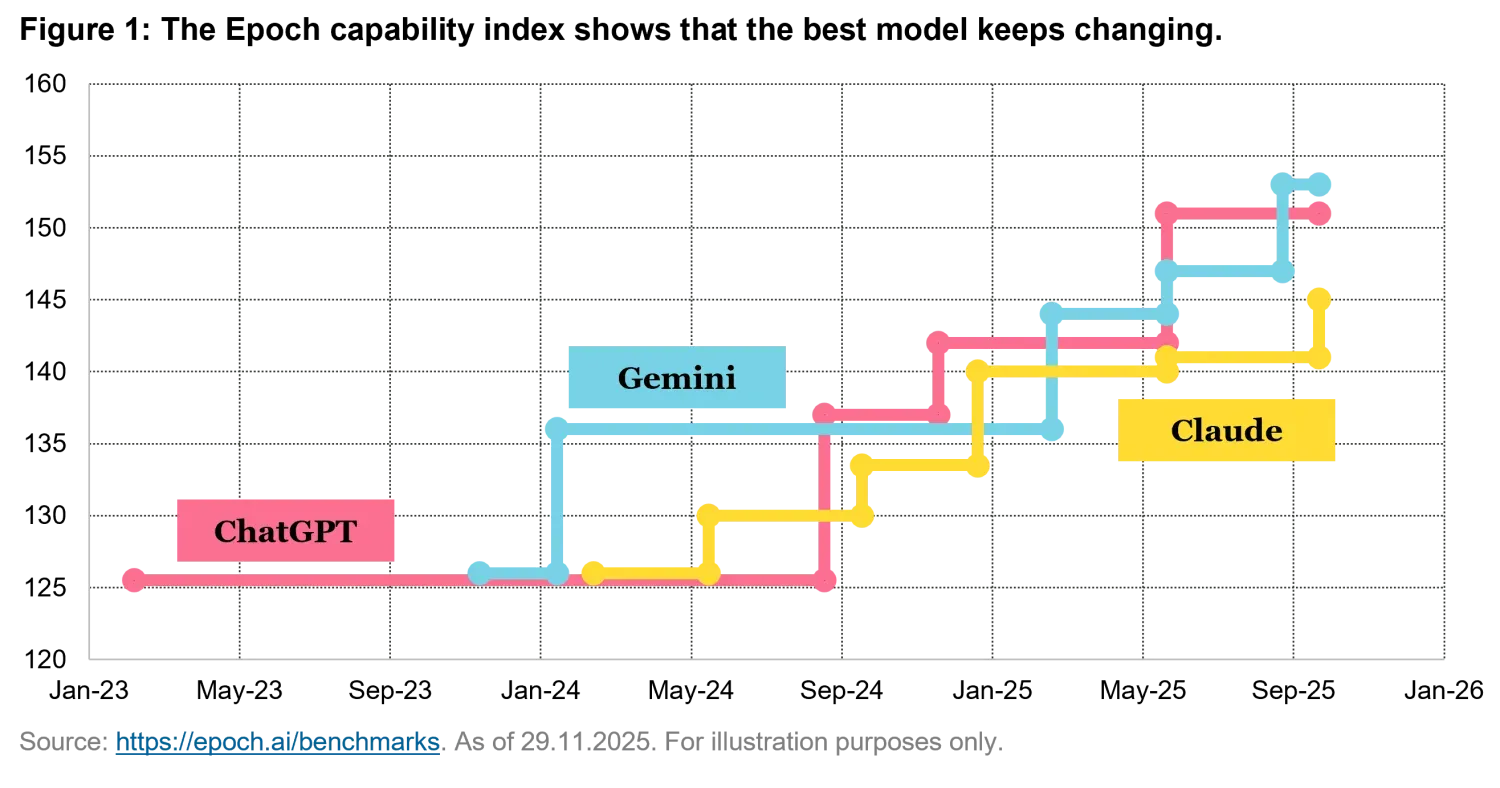
However, this position should be interpreted with caution. In our opinion, the competitive environment remains highly dynamic, and it is likely that future releases from OpenAI and Anthropic will reshape the rankings in the coming months. While Anthropic currently appears to be trailing in broad, aggregate evaluations like the above, its models continue to outperform peers in specific domains, most notably in coding-related tasks. Overall, the evidence suggests an unstable equilibrium rather than a settled hierarchy, with leadership contingent on both use case and evaluation criteria.
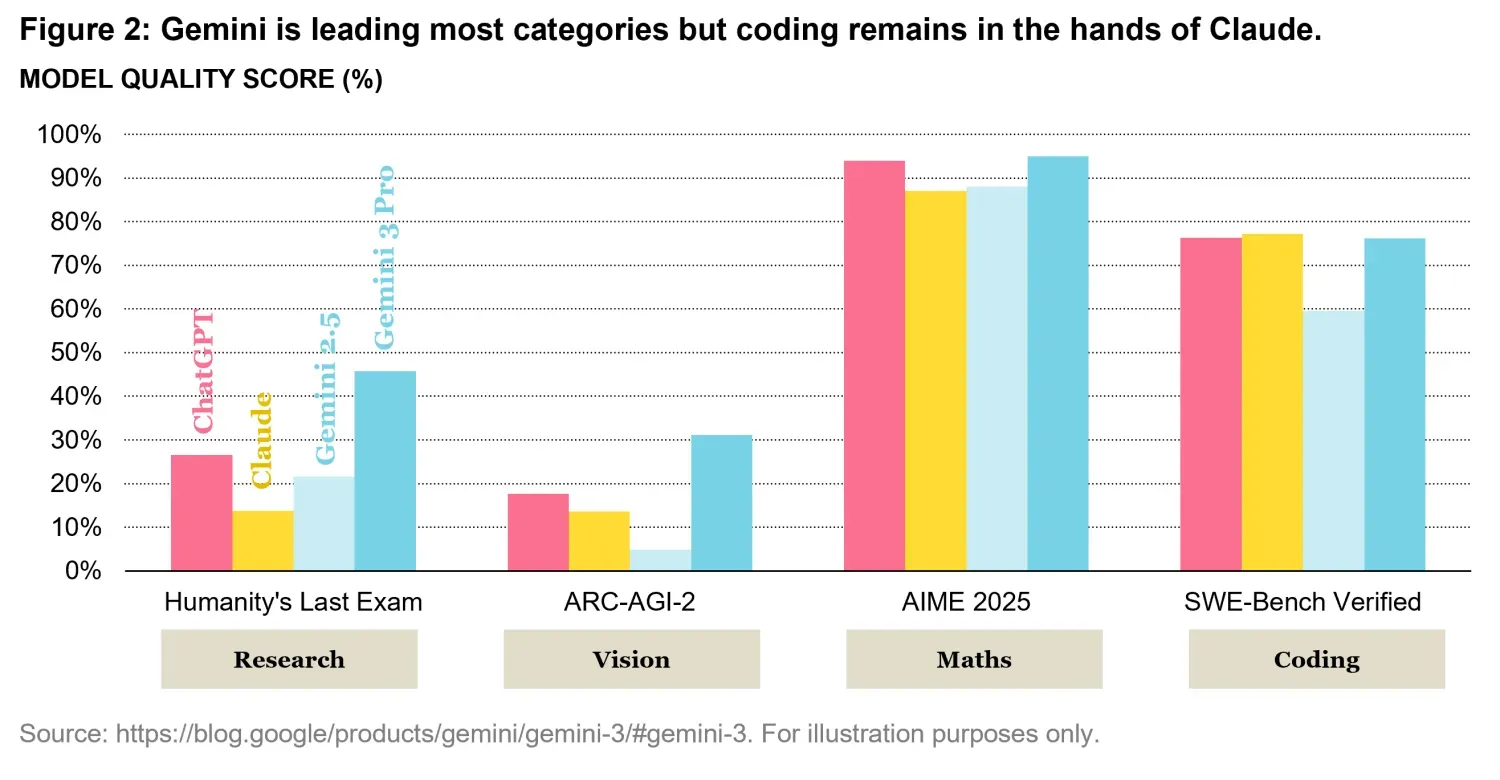
As illustrated in Figure 2, Google’s latest model currently leads across most evaluation categories like research, and vision, confirming its strong all-around performance. At the same time, Claude from Anthropic continues to set the benchmark in code generation, where it remains ahead of competing models even if just by a tiny amount.
These patterns point to a plausible future in which model providers increasingly specialize by task or industry vertical, fine-tuning their systems to excel in narrower, high-value domains rather than competing solely on general-purpose capabilities. Such specialization would mark a shift from a single “best” model paradigm toward an ecosystem of differentiated LLMs optimized for specific use cases.
A clear example of this move toward specialization is Harmonic, a startup focused on developing an AI-powered mathematical proof engine. Harmonic gained significant attention after winning a gold medal at the Mathematics Olympiad , becoming the first AI system to achieve this result while being able to formally prove its solutions and guarantee the correctness of the final outcome with full certainty.
This achievement represents an important milestone in model specialization and in the design of innovative system architectures that prioritize verifiability over probabilistic outputs. By ensuring mathematically proven results, Harmonic’s approach directly addresses one of the key limitations of current large language models, namely the risk of hallucinations. As noted by the company’s founders, the same methodology has strong potential applications in software development, where verified reasoning and correctness could bring substantial benefits to coding and code validation workflows.
Open or closed?
Another major aspect of the LLM landscape is the one between open- and closed-weight models. The major players discussed earlier primarily follow the same approach: models are kept behind closed doors and made available to users exclusively through paid API access. This method allows providers to retain full control over performance, updates, and monetization, while limiting transparency into how the systems are built and trained.
By contrast, other players, most notably Meta and China-based DeepSeek, have adopted a different strategy. They train large foundation models and release methodology papers and the model weights freely to the public (in practice these are massive parameter matrices containing billions of values). While open-weight models are accessible in principle, running them is far from costless. Deploying these systems efficiently requires substantial computational infrastructure and specialized expertise, making practical usage challenging and expensive for many organizations.
Despite these barriers, the open-weight approach fosters transparency, further research, experimentation, and facilitates private or sovereign use cases of large language models, where data may not be shared with third-party providers. As shown in Figure 3, open-weight models since July 2023 outnumber the closed-weight ones. In terms of quality, however, open models have historically lagged: in 2024 the gap was close to one year, narrowing to roughly six months in 2025.
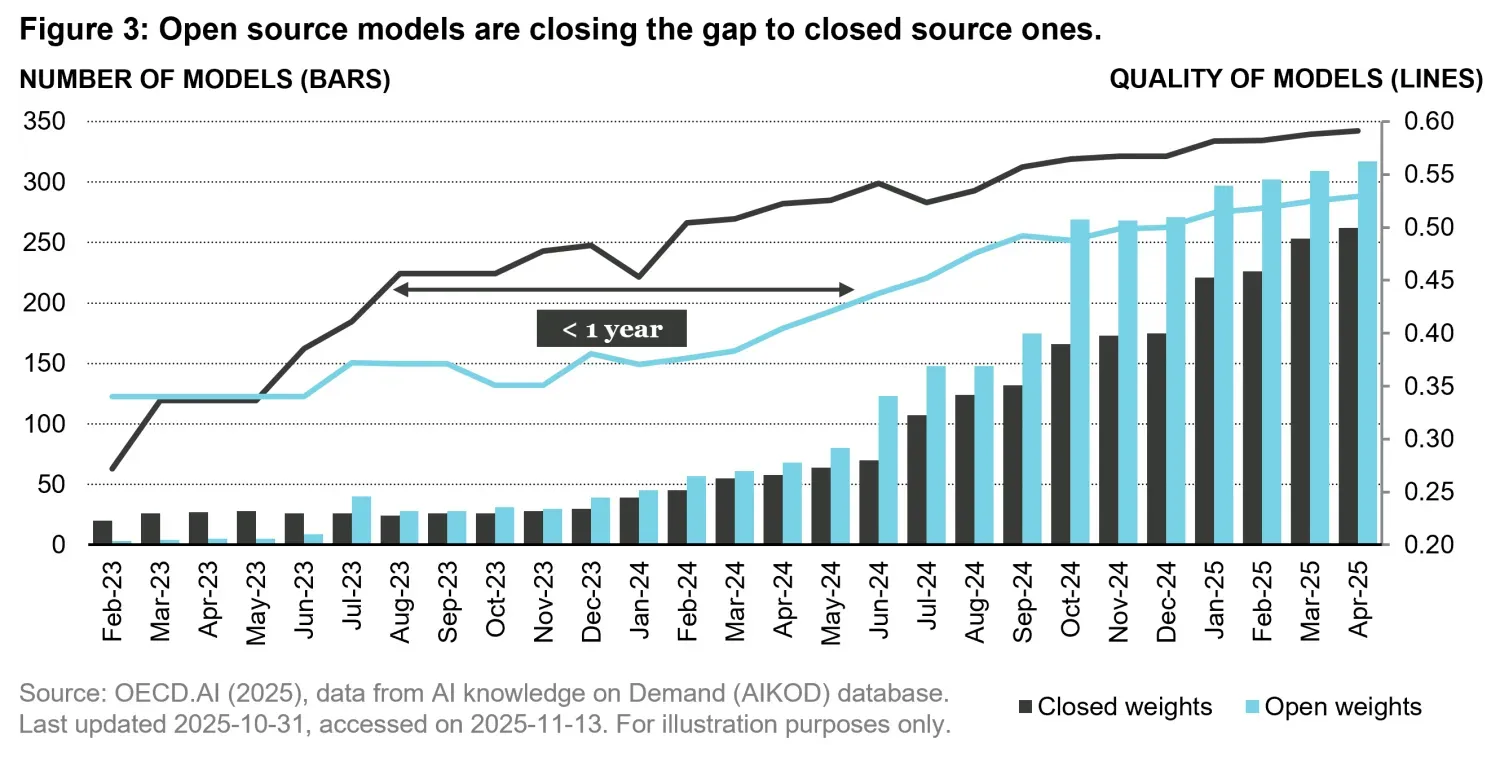
At the current pace of improvement, we believe open-weight models are likely to catch up and eventually surpass closed-weight alternatives, making their broader adoption increasingly difficult to ignore with potential major implication in the current big player’s commercial model. Open source (or in this case “open weights”) is not a new paradigm however. It has been a foundational driver of large-scale software innovation for decades, underpinning the success of technologies such as Linux, Red Hat, and MongoDB. A similar dynamic may now be unfolding in artificial intelligence.
China’s edge
On the research front, an interesting pattern is emerging simultaneously. Countries where most of the leading closed-model providers are located are producing fewer high-impact AI research publications than in previous years. As commercial incentives and proprietary development take precedence, research output appears to be more concentrated within corporate boundaries and less available to the broader scientific community.
In contrast, China is increasingly leading the global AI research publication landscape. A large share of recent high-impact publications originates from Chinese institutions, and many of the most prominent open-weight models are also developed there. As shown in Figure 4, China is currently the leading producer of high-impact AI research papers, with a publication share comparable to that of the United States and the European Union combined.
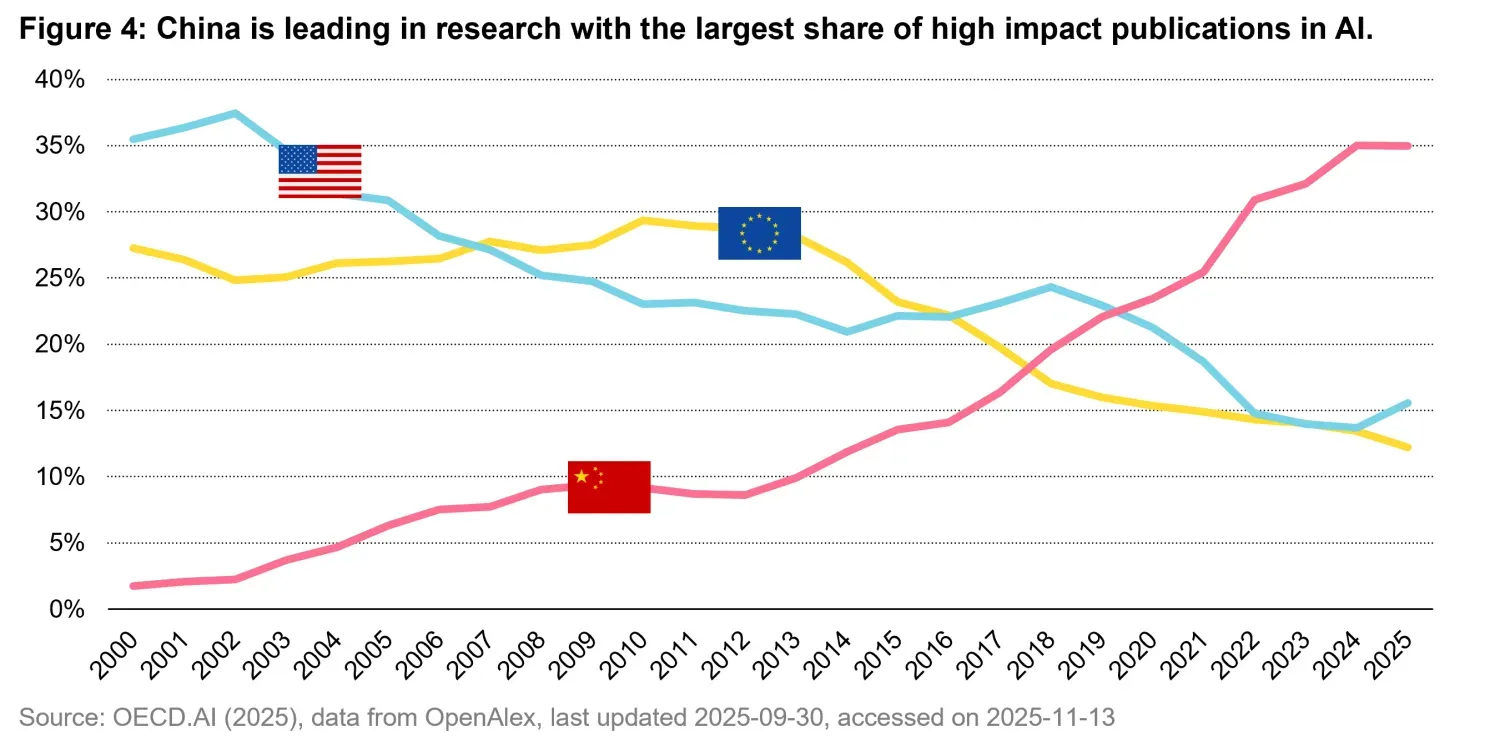
While this may seem surprising at first glance, it appears more coherent when viewed through a collaborative lens. By embracing open research and open-weight models, China may be deliberately leveraging the global research community to accelerate progress. This strategy may enable faster iteration, broader scrutiny, and collective innovation, potentially allowing advances in AI to occur at a pace that is difficult to match for proprietary development models.
As shown in Figure 5, China may also be well positioned in terms of energy generation capacity when compared to the European Union and the United States. This factor has become increasingly relevant over the course of 2025, as it has become clear that large-scale AI data centers are extremely energy intensive and that access to abundant, reliable power is a critical constraint on further model scaling and deployment. However, it is also expected that future innovations will significantly reduce energy demand for AI inferencing on a per output basis.
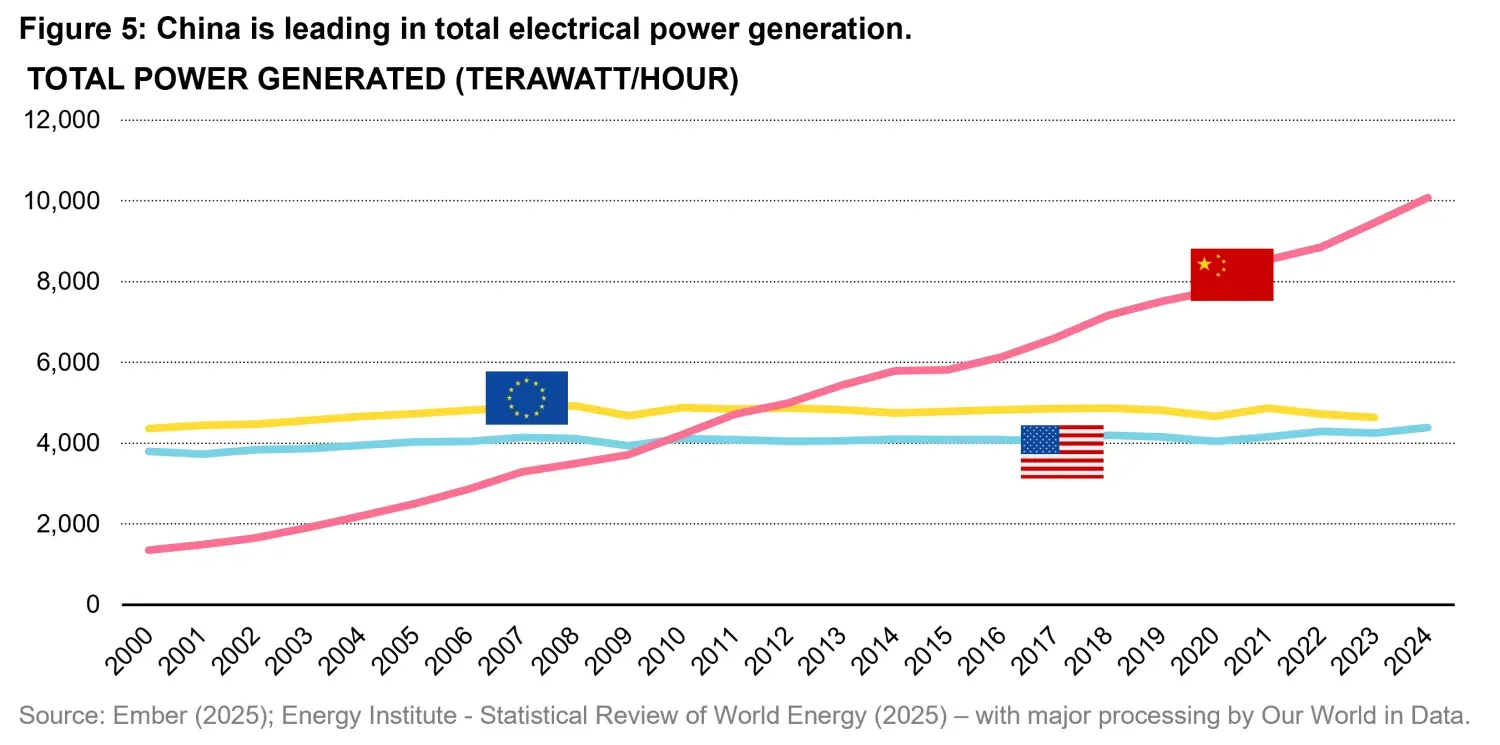
Overall, in our view China’s positioning in AI research, open weight models and energy advantage could translate into a significant competitive edge soon. The extent to which this advantage can be fully realized, however, will depend on China’s ability to develop and manufacture advanced GPUs and supporting hardware at performance levels comparable to those of American companies, whose most advanced products are currently under restrictions from sale in the Chinese market.
The regulatory landscape
The United States
In the United States, the regulatory approach to artificial intelligence has undergone a marked shift over the past two years. In 2023, President Biden’s Executive Order 14110 set out a framework aimed at promoting the safe, secure, and responsible development of AI. Following this initiative, AI-related legislative activity accelerated significantly at the state level. As shown in Figure 6, the number of state bills addressing artificial intelligence has increased sharply, rising to more than 130 and reaching a level roughly six times higher than in 2023.
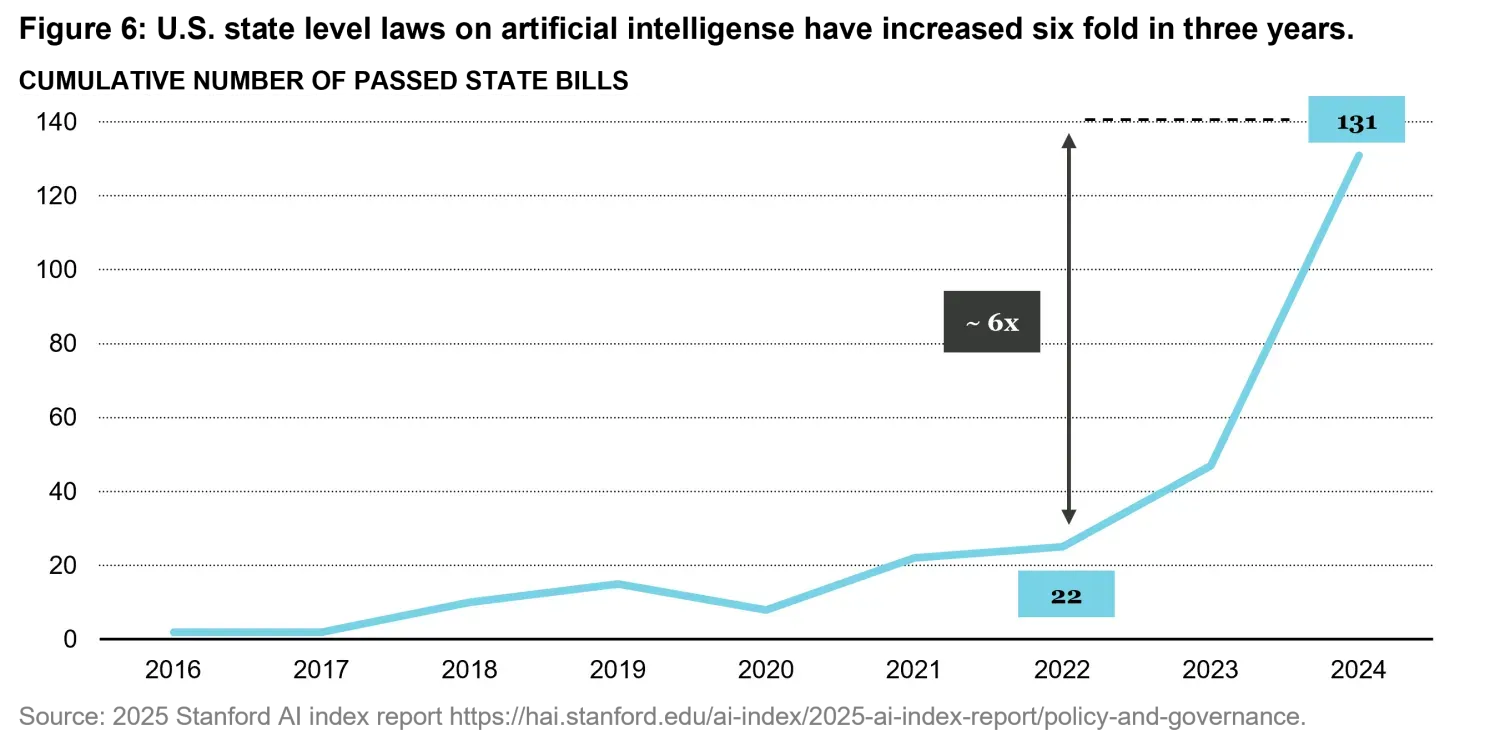
Since the beginning of 2025, however, the regulatory direction has changed. Under President Donald Trump, the focus has moved away from precautionary oversight toward policies explicitly designed to secure U.S. leadership in the global AI race. This shift reflects a more assertive and competitive stance, emphasizing speed of innovation and strategic dominance over risk containment.
The most recent executive actions (Executive Order “Ensuring a National policy framework for artificial intelligence” of the 11th of December) seek to streamline regulation and prevent it from becoming a barrier to technological progress, with the stated objective of ensuring that innovation is not slowed by fragmented or overly restrictive rules.
Three key arguments underpin the current U.S. position. First, federal policymakers argue that AI companies must be free to innovate without excessive regulatory burdens, and that state-by-state regulation creates a patchwork of up to 50 different regimes, significantly increasing compliance costs, especially for smaller firms and start-ups. Second, there is concern that some state laws risk imposing ideological constraints on AI systems. For example, legislation aimed at preventing “algorithmic discrimination” may, in practice, incentivize models to distort outputs in order to avoid differential treatment across protected groups. Third, certain state-level regulations are seen as extending beyond their jurisdictions, potentially interfering with interstate commerce. Taken together, these considerations illustrate a regulatory philosophy increasingly oriented toward national coordination, reduced friction, and competitive positioning in the global AI landscape.
European Union
In Europe, the regulatory landscape for artificial intelligence has taken a markedly different path from that of the United States. The European Union began this process early, structuring the AI Act in 2023, which was widely seen as a forward-looking and globally leading framework for regulating AI systems. The goal of the Act is to promote trustworthy and human-centric AI while safeguarding fundamental rights, health, safety, and democratic values.
However, implementation of the AI Act in 2024 has proven to be complex and, in some corners of industry and policy circles, overly burdensome. Critics argue that the detailed requirements are slowing innovation and creating significant compliance challenges for companies operating in Europe. A coalition of more than 40 European CEOs from firms such as ASML, Philips, Siemens, and Mistral publicly called for a “two-year clock-stop” on parts of the Act to allow more time for simplification and reasonable compliance. Meanwhile, many AI providers and tech policy experts have expressed concern that strict regulatory demands could delay product launches and deter investment relative to less regulated markets like the U.S. and China.
At the same time, the European Commission is already responding to these pressures. It has resisted proposals for a complete moratorium, stating that it will focus on making the rules work in practice while simplifying administrative requirements where possible. Italian political leaders, including former European Central Bank (ECB) President Mario Draghi, have underscored the need to adjust the regulatory framework to avoid stagnation in European AI competitiveness. Draghi has warned that overly strict rules risk leaving Europe behind in the global race, potentially constraining economic growth if the block does not adapt its approach in line with technological and market realities.
Despite concerns about regulatory burden, proponents of the EU’s approach argue that strong governance can build trust and protect fundamental rights, potentially turning regulatory clarity into an asset over the long term. The outcome of ongoing debates around simplification, timing, and balance between innovation and safety will shape whether Europe’s AI regulation remains a competitive advantage or becomes a drag on technological leadership.
China
China’s regulatory and strategic approach to artificial intelligence has evolved markedly over a short period of time, reflecting both changing global conditions and growing domestic capabilities. In 2023, China positioned itself as a strong proponent of openness and international cooperation in AI. Official statements emphasized that AI knowledge should be shared globally and that technologies should be made publicly available under open-source terms, while explicitly warning against the use of technological monopolies to erect barriers to access. This stance aligned with China’s support for open research, open-weight models, and broad participation from the international scientific community.
By 2025, however, the emphasis has shifted. While openness has not disappeared, it has been reframed within a much stronger narrative of strategic autonomy. Current policy language stresses the need for self-reliance, for maintaining control over critical AI technologies, and for firmly holding the initiative in AI development. The focus has also moved decisively toward application-oriented development, prioritizing the deployment of AI in industrial, economic, and strategic domains rather than purely academic leadership.
The contrast between these two positions highlights a pragmatic adjustment rather than a contradiction. In the earlier phase, openness served as a force multiplier, allowing China to accelerate progress by leveraging global collaboration. As domestic capabilities have matured and geopolitical constraints have intensified, the policy priority has shifted toward securing supply chains, reducing external dependencies, and translating research strength into real-world impact. In this sense, China’s current approach combines elements of open innovation with a clear strategic objective: ensuring that AI development remains both nationally controlled and economically sustainable.
Our predictions for 2026
Looking ahead to 2026, we expect the competitive dynamics among leading LLM model providers to remain intense. OpenAI is likely to release yet another more powerful generation of models, continuing its pattern of incremental but meaningful advances. However, we believe Google is ultimately well positioned to keep up with its competitors. With unparalleled access to computing infrastructure, deep in-house research talent, and substantial financial resources, Google represents one of the hardest competitors to displace in the long run.
At the same time, we anticipate the emergence of a growing number of smaller, highly specialized players that lead in specific vertical domains. Much as Harmonic is doing in mathematics, expert models optimized for narrow but critical areas—such as law, medicine, engineering, and scientific research—are likely to gain traction. These systems will prioritize accuracy, verification, and domain expertise over broad generality.
By contrast, we see artificial general intelligence (AGI) as still distant and impossible to achieve simply through large language models. For now, the bulk of measurable value creation will continue to come from the automation of repetitive office and knowledge-work tasks across industries, rather than from fully autonomous systems.
From a geopolitical perspective, the United States is expected to stay on its current innovation-driven trajectory. In Europe, we anticipate a gradual easing of regulatory pressure, as policymakers seek to balance safeguards with competitiveness. This shift should enable greater investment flows into the region and support a renewed wave of AI-driven innovation.
China, however, may emerge as the most disruptive force in 2026. We expect Chinese open-weight models to reach performance levels comparable to closed-source American systems, while being offered at a fraction of the cost. If this materializes, it could significantly accelerate adoption, reinforce China’s leadership in AI, and begin to reshape the global competitive landscape.
Conclusion
The Large Language Models landscape at the end of 2025 is defined by diversity, specialization, and intense global competition. No single provider dominates, and progress is increasingly shaped by infrastructure, research strategy, and the ability to deliver reliable, verifiable results in specific domains. Open versus closed models, differing regulatory approaches, and national strategies in the United States, Europe, and China are all influencing the pace and direction of development. Beyond LLMs, AI is already being adopted in practical applications across industries—from mathematics and coding to investment and knowledge work—demonstrating tangible economic value. At Vontobel for example, our internally developed AI system powers the core investment strategy for a global equity fund since 2024, highlighting the abilities of AI to deliver real-world solutions to complex problems. Overall, the field is evolving into a multipolar ecosystem, where innovation, specialization, and strategic deployment determine which players and regions lead the way.
Sources
https://www.oecd.org/en/topics/artificial-intelligence.html
https://www.euronews.com/next/2025/07/03/europes-top-ceos-call-for-commission-to-slow-down-on-ai-act
https://www.euronews.com/next/2025/09/22/eu-commission-rebuffs-calls-to-press-pause-on-ai-act
Global Artificial Intelligence Governance Initiative, statements by President Xi Jinping, October 2023.
Remarks by President Xi Jinping at a Politburo study session on AI, April 2025.
Important Information: The content is created by a company within the Vontobel Group (“Vontobel”) for institutional clients and is intended for informational and educational purposes only. Views expressed herein are those of the authors and may or may not be shared across Vontobel. Content should not be deemed or relied upon for investment, accounting, legal or tax advice. Past performance is not a reliable indicator of current or future performance. Investing involves risk, including possible loss of principal. Vontobel makes no express or implied representations about the accuracy or completeness of this information, and the reader assumes any risks associated with relying on this information for any purpose. Vontobel neither endorses nor is endorsed by any mentioned sources. Quantitative inputs and models use historical company, economic and/or industry data to evaluate prospective investments or to generate forecasts. These inputs could result in incorrect assessments of the specific portfolio characteristics or in ineffective adjustments to the portfolio’s exposures. The predictions and projections provided are based on available information, historical trends, and current assumptions at the time of analysis. They are not guarantees of future outcomes and are subject to change due to unforeseen factors, market conditions, or new data. As market dynamics shift over time, a previously successful input or model may become outdated and result in losses. Inputs or models may be flawed or not work as anticipated and may cause the portfolio to underperform other portfolios with similar objectives and strategies. The AI models deployed are predictive by design, which inherently involves certain risks. There are potential risks associated with AI tools as these tools, being relatively new, may harbor undetected errors or security vulnerabilities that may only surface after extensive use. The AI investment strategies are proprietary, as such, a client may not be able to fully determine or investigate the details of such methods or whether they are being followed.
About the authors

About the authors
Topics:
Related insights

2026: Multi Asset Reloaded - Investors (Still) Need Diversification

Quant 2.0 - The AI Revolution

Global rates: a mirage of diversification

The signals beneath the surface

When Many Own the Same Few
