In the previous article of our expl(AI)ning series, we explored the foundational concepts of neural networks, and demonstrated how artificial intelligence was largely inspired by its biological equivalent. The similarities go farther in that, like biological intelligence, artificial intelligence is also one where you do not need to understand every single piece to create wonders at the aggregate level. While the inner workings of each neuron, or small groups thereof, are still obscure to medical science, several billions of them stacked together produce the wonder called ‘the human brain’. The same occurs for artificial intelligence.
What does that mean for those of us that use AI to manage investments? Do we need to forego the understanding of the individual pieces when putting them together into an AI system? Is that acceptable from a fiduciary duty perspective? How does AI change our roles as developers of quantitative strategies?
In this article, we expose investors to the revolution that not many are speaking about: the mental re-wiring that AI is causing in the quant community. Most quants that are active in the industry today were educated with the mindset of postulating a model for reality based on common economic theory, and fitting data to it . Models that are written in mathematical form are typically ‘hard to digest’ for non-practitioners. They have few parameters that are left undetermined at first and then fit by looking at the past*. When AI drives decisions, this process becomes obsolete. De facto, with AI powering an investment strategy, AI decides the model too. Is there anything left to the creativity of practitioners? In short, yes. If we want AI to be put in a position to find the best model, whichever that is, we need to design the architecture properly, and feed as much data as possible.
In this article, we prove this assertion by looking at how specific architectures (and data feeding them) were indeed the breakthrough element when tuning AI systems to beat humans in several aspects of life. Specifically, we’ll investigate vision, language, and tabular data.
Vision
Last time, we introduced the core concepts of classification and regression. Now, let’s apply that to a practical example: the task of classifying images to determine whether they depict a cat or a dog. How would you instruct a machine to make this distinction? One approach could be to manually write a set of predefined rules. You might try to describe the shapes, texture patterns, or facial features that define cats and dogs. But think about the complexity of this task: you'd need to account for every possible variation—different breeds, lighting conditions, angles, even images where only part of the animal is visible. The number of rules would quickly become overwhelming. Trying to define an exhaustive list of instructions for every possible scenario is not only impractical but impossible.
Traditional programming methods fail here because they can’t handle the sheer complexity and subtle variations present in image data. Images, unlike numerical or textual data, consist of thousands or even millions of pixels, each carrying information about colour, intensity, and position. The patterns that make up an image are often too intricate to be represented by explicit logic or predefined rules. For instance, how do you explain to a machine the difference between a fuzzy cat tail and a dog’s ear when they’re both similar in shape and colour?
This is where neural networks come into play. Convolutional neural networks (CNNs) are specifically designed to handle the complex structure of image data. At the heart of CNNs is a process known as convolutions. In simple terms, a convolution is a mathematical operation applied to small regions of the image, allowing the model to extract specific patterns such as edges, textures, or shapes.
You need to imagine the convolution process as a filter sliding across the image, scanning it piece by piece, detecting patterns. In the early layers of the network, these filters might detect basic structures like lines or corners, while deeper layers begin to identify more complex features such as eyes, fur patterns, or the overall shape of the animal as shown in the representation of Figure 1.
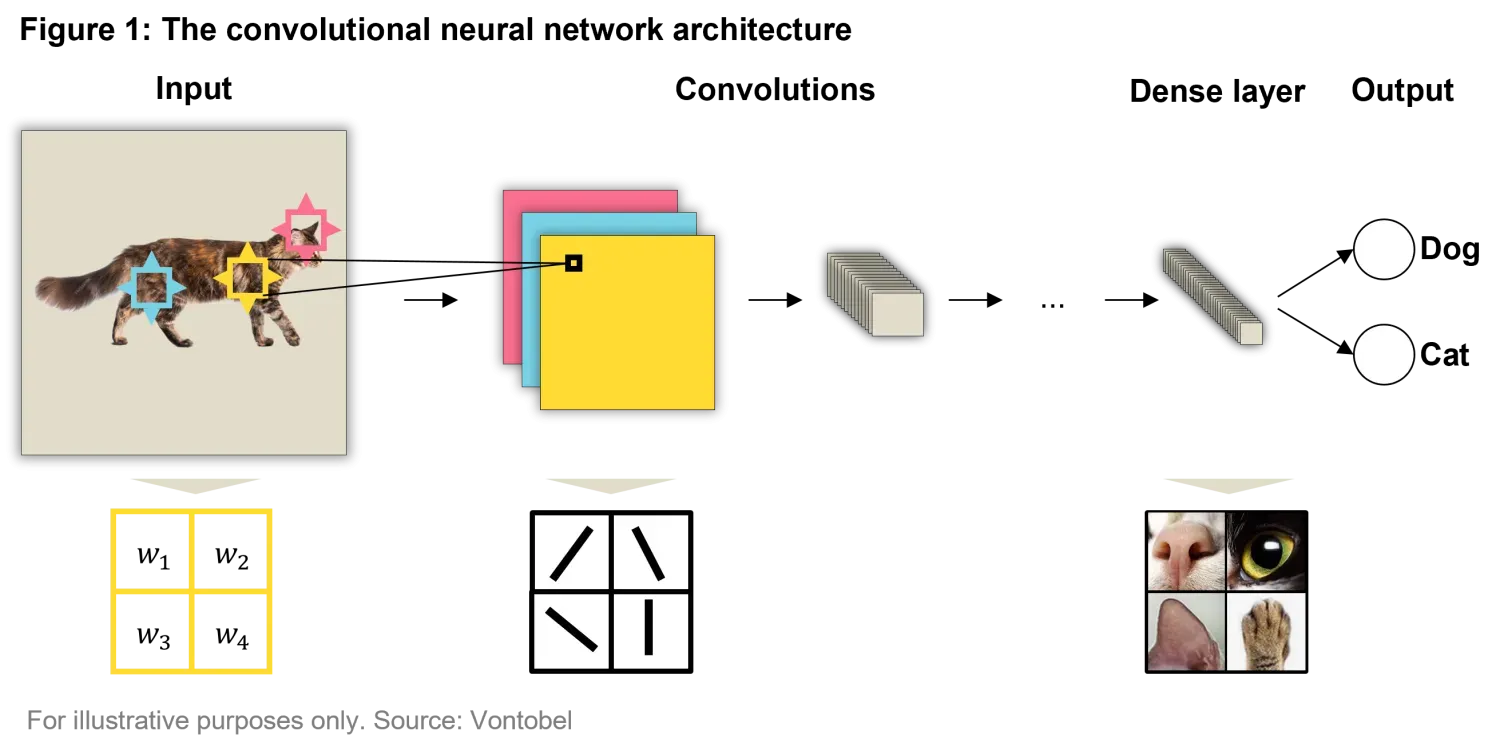
In a CNN, as you move from the left to the right, as depicted in Figure 1, filters decompose a large image into multiple, smaller images containing the features that capture the most relevant information to the classification objective. By using operations like pooling (a special kind of filter which down samples the data even more), CNNs simplify and condense data, making it more manageable while retaining the critical information. Finally, after these features are extracted, they are passed to a more traditional fully connected (dense) layer of the network, which takes many small features and spits out the probability that the image contains a dog, a cat, or other animals (assuming that such is the classification objective).
The key takeaway here is that having numerous small filters that learn how to extract features was a breakthrough idea. Paired with massive amounts of carefully labelled and easily available data, this approach led to the stunning success of models like ResNet1, which clinched the top spot in the 2015 ImageNet competition. This combination—smart filter choices within a powerful architecture and abundant data—has proven to be the winning formula for tackling complex image classification challenges.
Language
Another field where AI has brought significant advancements is natural language processing (NLP). Unlike images though, natural language is inherently sequential.
For AI to truly understand language, it must grasp how the meaning of each word shifts based on its relationship with surrounding words. Early attempts at NLP relied heavily on rule-based systems, which were sets of hand-coded rules dictating how language should be processed. For instance, if you wanted to translate or understand sentences, you’d have to write specific rules for grammar, syntax, and vocabulary. This approach worked for highly controlled environments but quickly became unmanageable for real-world language complexities. Imagine trying to manually write rules to account for all possible uses of each word, e.g. "bank"—which could mean a financial institution or the side of a river—depending on the context.
As language evolved, capturing these nuances became impossible through rule-based models alone. These systems lacked flexibility, failed to generalize across different languages and contexts, and could not scale to the vast diversity of human expressions. Although numerous attempts were made using varying versions of the CNN architecture, the real breakthrough came with a mechanism that takes into account of the time axis in data.
Enter Transformers . Introduced by Vaswani et al. (2017)2, the Transformer neural network architecture was a breakthrough in NLP. Its most significant innovation is the self-attention mechanism, which allows the model to weigh the importance of each word in a sentence relative to all the others, even if those words are far apart in the sequence.
For example, in the sentence “The bank by the river was flooded,” the model can understand that "bank" relates to "river" by looking at the broader context. This mechanism is a powerful improvement over older models that could only capture local context, often missing longer-range dependencies. Figure 2 provides a simplified visualization of how the transformer’s self-attention mechanism works , showing how the model dynamically assigns weights to each word based on its relevance to the others in a sentence.
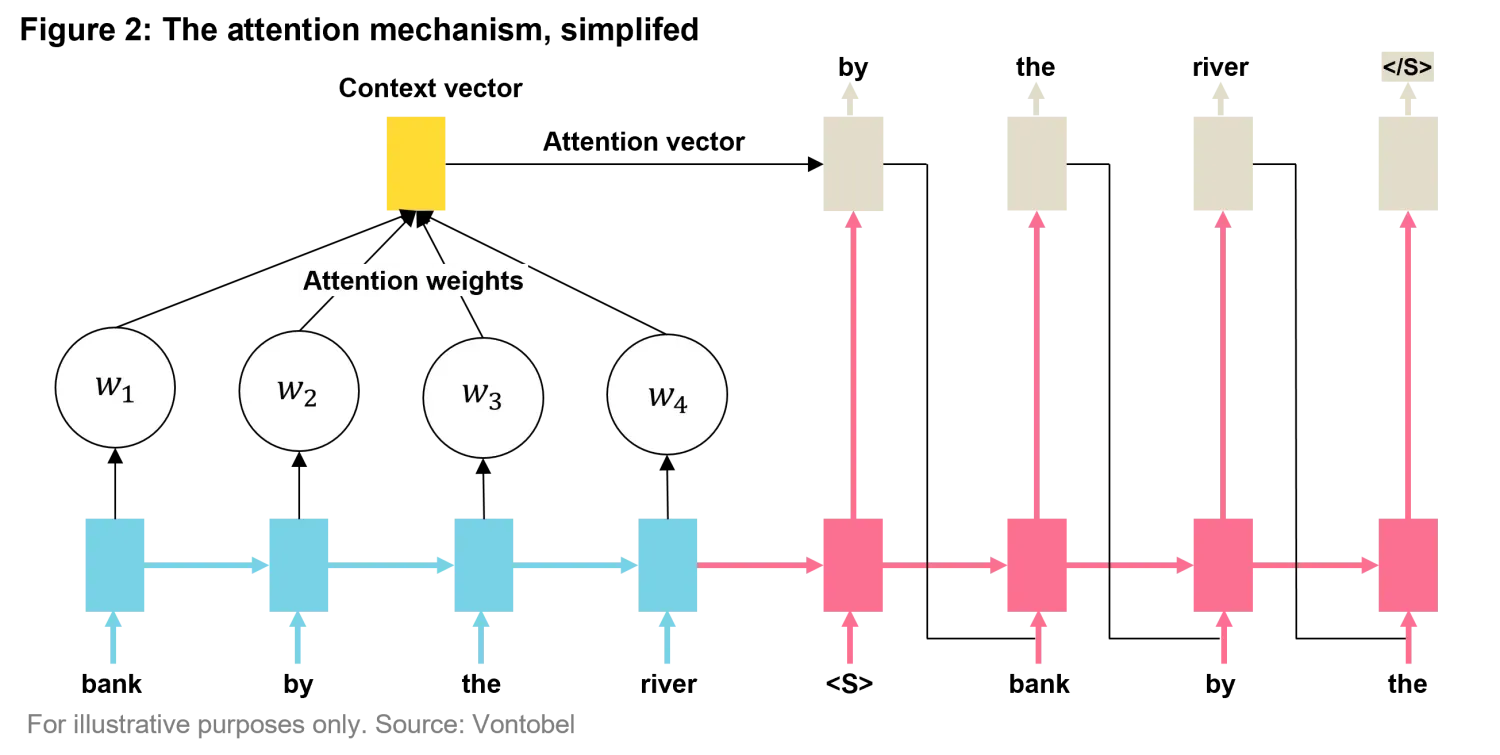
One of the most prominent applications of this architecture is the GPT (Generative Pre-trained Transformer) series, which uses the Transformer structure to process and generate human-like text. This is the engine lying behind ChatGPT and most of the latest language models. By pre-training on massive datasets of text, GPT models can then be fine-tuned for specific tasks, such as translation, summarization, or even answering questions. This combination of a cutting-edge architecture with large-scale data produces state-of-the-art results in many language tasks, enabling models like GPT to handle tasks that were previously unthinkable for machines. These models take the characteristics of context-awareness of transformers and combine it with generative capabilities. This was not an easy task and required large amounts of good quality data. Commercial GPT models are trained on more than 300 billion words datasets, the equivalent of around 570 gigabytes of data.
In essence, the majority of large language models (LLMs) have this architecture and their (simplified and intuitive) task is to generate the best next word or single word given the knowledge embedded in training and an input prompt. Now that you know that LLMs still predict one word at a time, you might be more forgiving if sometimes a generated text doesn’t always make entirely sense. That is why pure language models do not yet beat humans at maths for instance, but we’re probably a few hours away from that.
Transformers, like CNNs, represent an evolution of neural networks. This architecture proved to be far more effective for handling the specific characteristics of language, such as context and sequence.
Tabular data
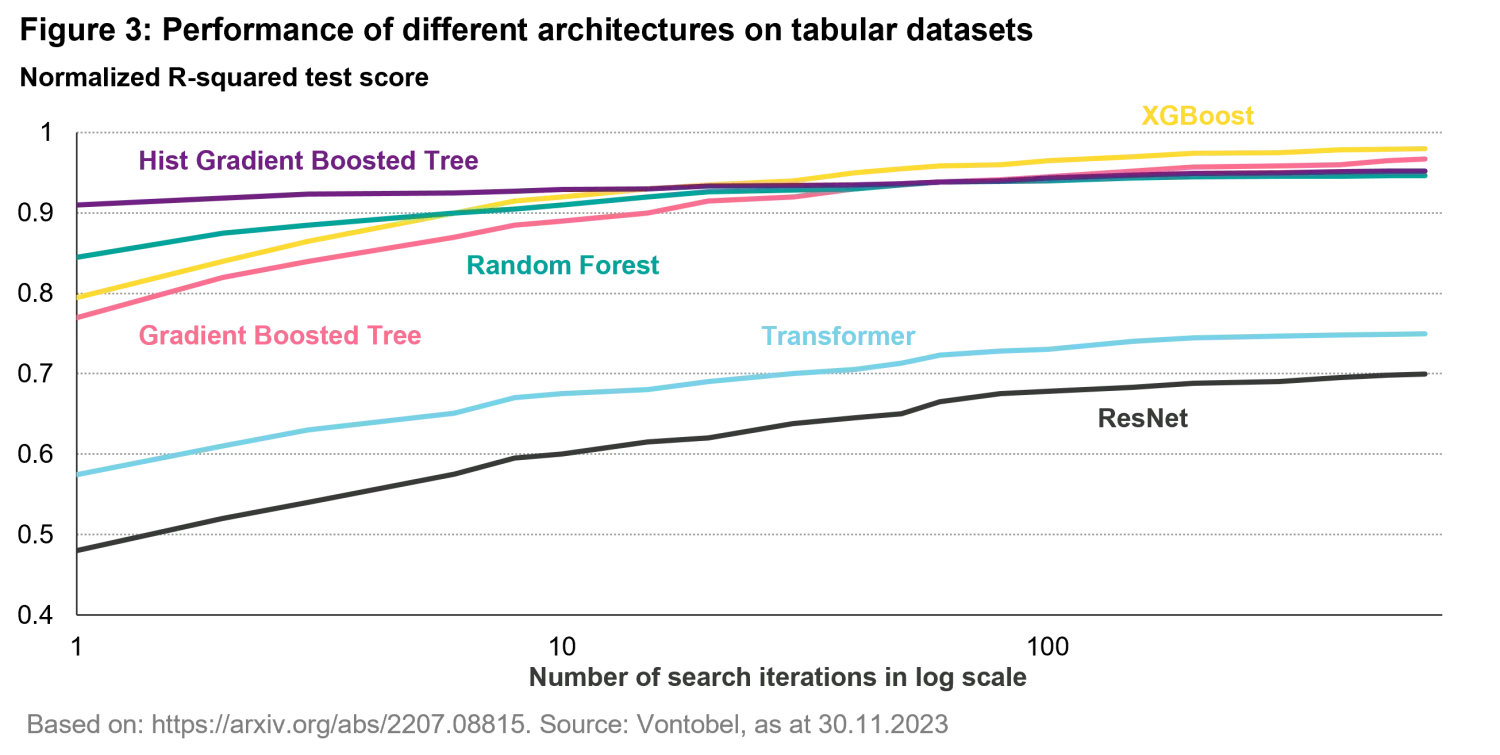
Now, let’s switch gears to another common form of data: tabular data – yes the same data you usually consume via spreadsheets. This type of data is especially relevant in fields like finance, where structured datasets are abundant and crucial for making predictions. By now it won’t be a surprise for you to hear that, while neural networks have shown remarkable performance in tasks like vision and language, in their CNN and Transformer architectures, they aren’t always the best solution for structured, numerical datasets. In fact, models based on decision trees, particularly advanced artificial intelligence techniques like Gradient Boosted Trees (GBT), often outperform neural networks when working with tabular data. Figure 3 taken from a study of Shwartz-Ziv et al (2022)3 shows how tree-based models like Random Forest and XGBoost outperform neural network architectures (like the ones discussed before ) most of the times when using tabular numerical data.
Why do decision trees, and their advanced variants like GBT, perform better on tabular data? The strength of decision trees lies in their ability to handle categorical variables (such as stock sectors in finance), manage missing data, handle features with different scales (hence not needing normalization) and capture intricate feature interactions—all with minimal preprocessing. For instance, when predicting stock prices based on factors like earnings, valuation ratios and price momentum, decision trees are highly effective at spotting non-linear relationships and breaking down these interactions into manageable, interpretable splits.
The Gradient Boosting technique introduced by Friedman, J. H. (2001)4builds on the idea of combining multiple simple models (typically very simple decision trees) in a sequential manner. Each new tree added to the model attempts to correct the errors of the previous one, effectively boosting the overall performance. This iterative process creates a robust model that excels in handling non-linear patterns and complex interactions present in tabular data, making it especially useful for financial predictions and other structured datasets. Models based on boosted trees can easily reach several hundred thousand subtrees of various depths. In Figure 4 we examine a simplified example of the resulting building block tree structure of a gradient boosted model when learning to predict stock returns from a simple dataset of fundamental variables and macroeconomic indicators
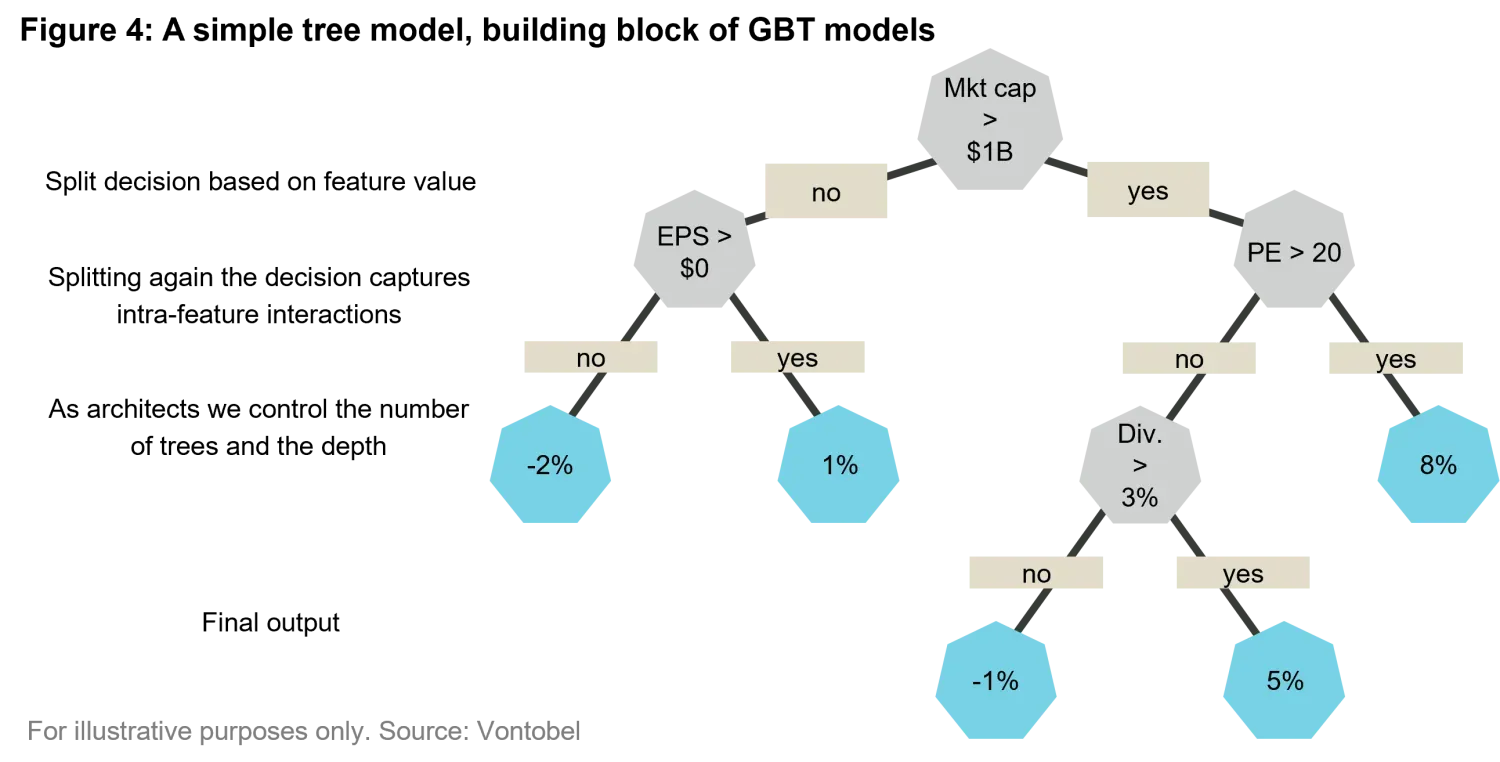
The key takeaway here is that trees are often the better tool for structured data, while neural networks shine with unstructured data like images or text. For tasks that involve relationships between specific numerical or categorical variables, data + the right model architecture—in this case, tree-based models—can significantly improve prediction accuracy and reliability.
Conclusion
We've highlighted how specific architectures (coupled with sufficient data) make or break AI performance in specific tasks. In a world where AI matters more, postulated models matter less, which challenges the need to study intricate mathematical modelling in the first place. What’s the point of going through extensive (and sometimes painful) mathematical descriptions of the world if AI can solve it all, provided we find a way to re-arrange architecture components in a certain way, and feed enough data? The question is legitimate, and one that challenges humankind at its heart.
Humans, and especially scientists, are trained, motivated by, and rewarded for finding the formula that underlies the world, the equations that God used to create the world. That permeated human quests for centuries. Do we need to give that up? Not quite. We argue that you still need intuition to put the bricks together to form the right AI system for your specific problem. This coupled with the right data and learning algorithm leads to the true magic.
We mentioned that AI has demonstrated to solve many practical problems once thought unthinkable for machines to solve. But where are we as it relates to investments? After all, we have not seen an investment strategy out there that delivers returns without losses day in and day out. Why is that? It has to do with the complexity of the problem, an aspect that we will elaborate upon in the next piece of the series.
* Fitting is typically an exercise of saying ‘which set of parameters would make this model closes to the observed data in the past?’.
1. He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 770-778.
2. Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 30, 5998-6008.
3. Shwartz-Ziv, R., & Armon, A. (2022). Why do tree-based models still outperform deep learning on tabular data? Advances in Neural Information Processing Systems, 34, 5978-5990.
4. Friedman, J. H. (2001). Greedy function approximation: A gradient boosting machine. Annals of Statistics, 29(5), 1189-1232.
Important Information: The content is created by a company within the Vontobel Group (“Vontobel”) and is intended for informational and educational purposes only. Views expressed herein are those of the authors and may or may not be shared across Vontobel. Content should not be deemed or relied upon for investment, accounting, legal or tax advice. It does not constitute an offer to sell or the solicitation of an offer to buy any securities or other instruments. Vontobel makes no express or implied representations about the accuracy or completeness of this information, and the reader assumes any risks associated with relying on this information for any purpose. Vontobel neither endorses nor is endorsed by any mentioned sources. AI-driven investment strategies are not available in all jurisdictions.

