In the first part of this series, we explored the theoretical foundations of model ensembles, showing why combining forecasts can lead to more accurate and robust predictions than relying on a single model. We highlighted insights from classic forecasting literature—such as robustness against structural shifts and protection against model misspecification—that remain just as relevant when building artificial intelligence (AI) models today.
In this second part, we move from theory to practice. We look at how ensembles can be constructed in AI and machine learning, what kinds of diversity among models actually matter, and how different ensemble strategies—from simple averaging to more sophisticated approaches like Bagging, Boosting, and Stacking—compare in real-world settings. Finally, we turn to the financial domain and examine how ensembles are being applied to improve stock return forecasts, drawing both on academic research and industry experience.
How To Build Model Ensembles?
In principle, different models could be obtained along various dimensions, for example:
- Different machine learning methods – Combining linear models (which capture broad trends) with non-linear models like Decision Trees or Neural Networks (which can capture complex interactions and local patterns) allows the ensemble to approximate a wider range of functional forms. Different algorithms possess different biases, leading them to learn distinct aspects of the data-generating process.
- Different training parameters – A crucial element concerns how model parameters are selected. For example, the training and validation windows could be varied to obtain different forecasts. Combinations of forecasts can reduce the impact of such choices on the prediction.
- Combining fundamental and AI-driven models – Fundamental models, often based on company financial statements and economic indicators, might capture signals related to long-term intrinsic value. In contrast, AI-driven models, frequently trained on market data (prices, volume) or alternative data (news sentiment), may be better at capturing shorter-term market dynamics, momentum effects, or behavioral patterns. An ensemble that integrates both could provide a more holistic view.
- Different return horizons – The factors driving stock returns over a 5-day horizon likely differ from those influencing 30-day or 1-year returns. Models optimized for different horizons are, by construction, looking at different dynamic processes and information sets, making their combination potentially powerful.
Of course, the open question remains how different models should be combined in practice to build an ensemble model. The classic literature also investigates this question. First, it turns out that a simple average of multiple forecasts is difficult to beat, even by combinations that attempt to give more weight to the “best” models or select the “single” best model (Palm and Zellner, 1992). Similar to the problem of portfolio optimization (Uppal, Garlappi and DeMiguel, 2009), forecast optimization requires estimating the optimal weight of each forecast, which is typically measured with low accuracy. In particular, optimization requires estimating the correlation between forecasts to find the optimal solution, which in turn requires a large number of parameters to be estimated. Any optimized solution is then likely to suffer from overfitting, effectively favoring the model that happens to fit the historical sample best rather than the one with true predictive power.
Second, in some situations, a simple average can likely be improved. For example, if the variance of forecast errors differs by a large degree, then it is reasonable to give higher weights to forecasts with lower forecast error variance (Clemen and Winkler, 1986). Similar to before, this argument resembles the “minimum variance” portfolio in portfolio theory, in which assets with lower variance are given a greater weight. Such “mildly” optimized forecasts have been shown to benefit further from shrinkage towards the simple average (Diebold and Pauly, 1990), or by trimming extreme forecasts. Intuitively, these “mild” optimization methods attempt to incorporate some information about past performance without succumbing to the full complexity and instability of unconstrained optimization.
In fact, there is a tradition of some kind of model averaging “within” specific machine learning models:
- Bagging – Multiple models (e.g. decision trees) are trained on different subsets of the data, and their outputs are averaged or voted on to make predictions (Figure 1). The goal is variance reduction. The Random Forest is an example of this technique.
- Boosting – Models are trained sequentially, with each model improving upon the errors of the previous one (Figure 1). The potential strength lies in bias reduction. Gradient Boosting Machines (GBM) are an example.
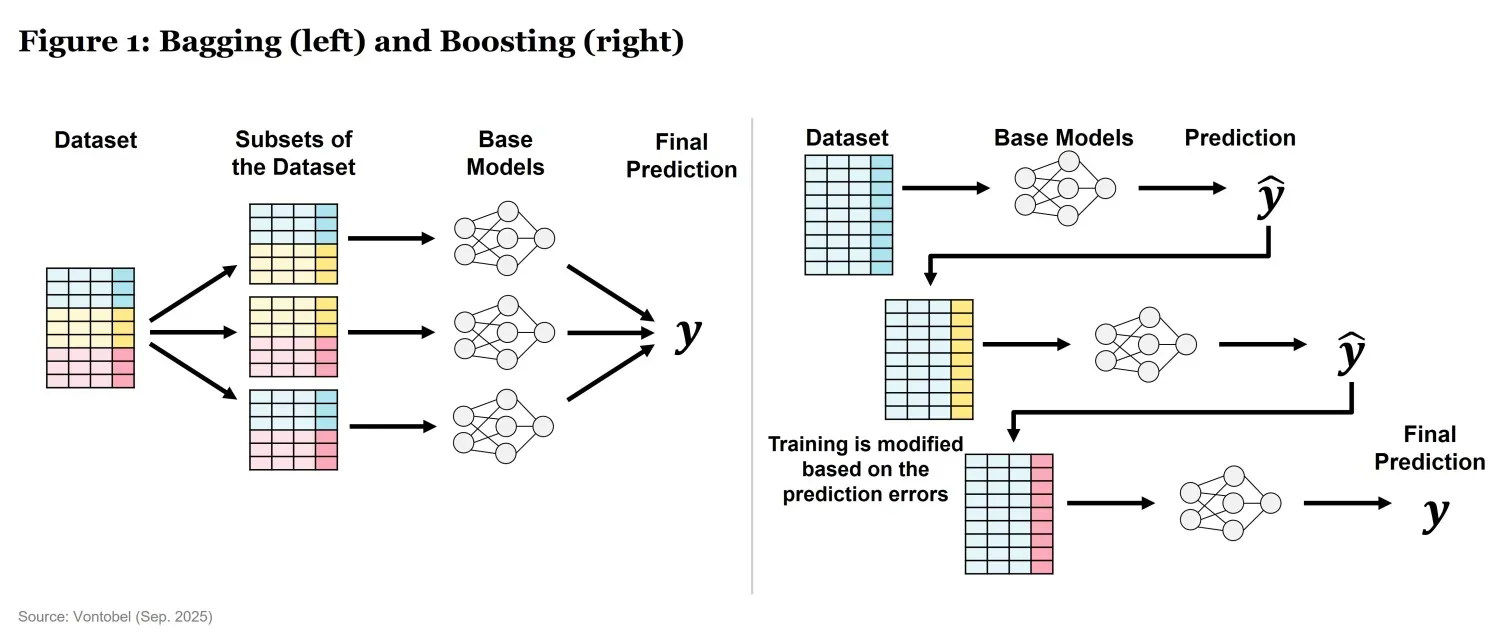
However, the machine-learning counterpart of the classic forecasting literature is when the analyst wants to combine “across” different model predictions:
- Simple Model Average – Multiple models (e.g. Random Forest & Neural Networks) are trained on the same data, and their outputs are averaged to make predictions (Figure 2).
- Model Stacking – Different models are combined at a higher level, often using another model (meta model) to determine the best way to integrate predictions (Figure 2).
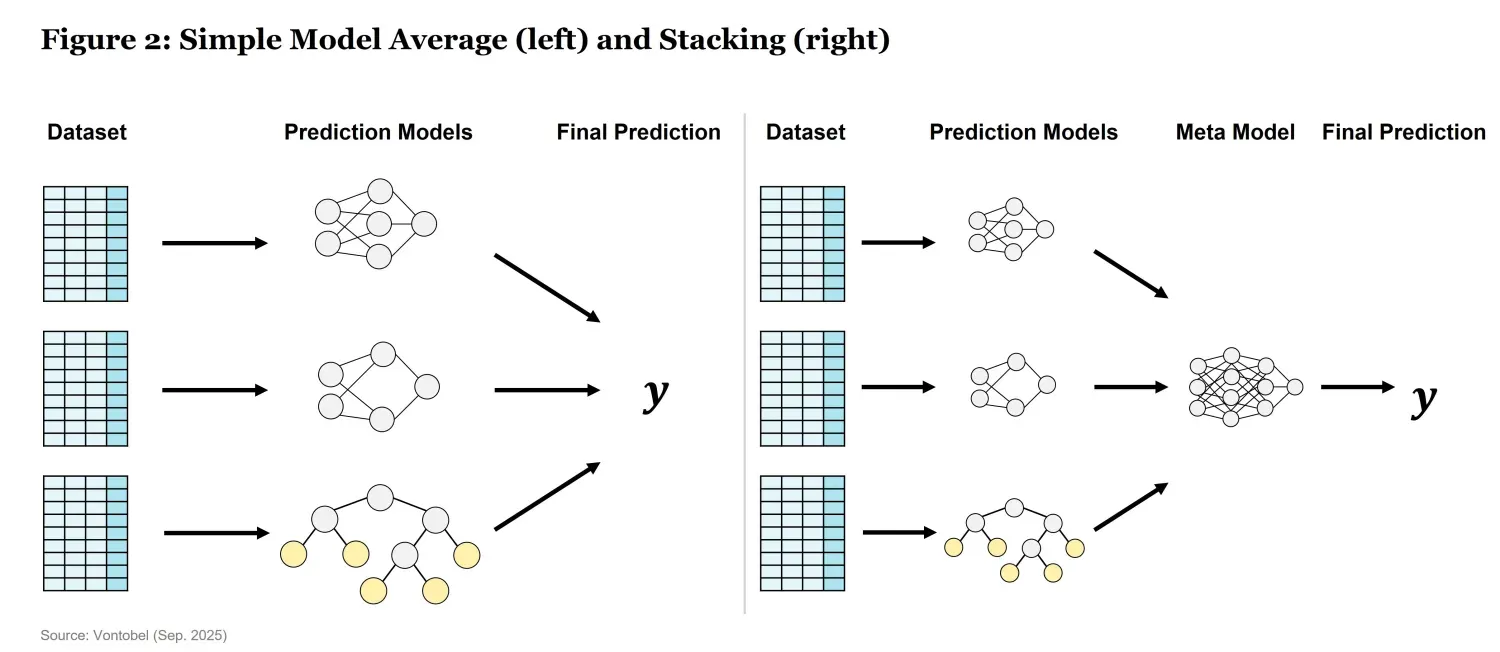
Machine-based forecasts suffer from the same problem of estimating the optimal weights of different forecasts based on a relatively limited amount of available data. Therefore, the arguments in favor of a simple model average or, at most, “mild” stacking of models, as set out in the classic literature, seem to remain valid. Of central importance will be that the models are of different types (e.g. Support Vector Machines, Neural Networks, Tree-based models). Diversity is a necessity that allows the ensemble to capture a wider array of patterns in the data, as different model types have different strengths and weaknesses.
Other reasons that speak against complex ensemble models are the computational costs, an increased black box problem, and overfitting. While ensembles improve accuracy, they come with trade-offs. Complex ensemble models can dramatically increase runtime and computational costs. Running multiple models instead of one increases training and inference time. More computational resources are needed, which can be costly, especially for large-scale financial applications. Furthermore, complex ensemble models come with the risk that they lack transparency and are difficult to interpret. Finally, the process of developing and selecting (complex) ensemble strategies can facilitate overfitting and ultimately lead to worse predictions.
Applying Model Ensembles to Predict Stock Returns
This section presents a selection of successful ensemble models. We first review recent articles in academic research. Afterwards, we provide insights on ensemble models that are successfully used by Vontobel.
Academic Research
Model ensembles to improve stock return forecasts have been recently studied in a series of research articles. Three examples from the recent literature are briefly introduced:
Rasekhschaffe and Jones (2019): US and global stocks are predicted with 194 variables using different ML methods like Adaboost, Tree-Boosting, Neural Networks, Support Vector Machine. They find that “with sensible feature engineering and forecast combinations, machine learning algorithms can produce results that dramatically exceed those derived from simple linear techniques like OLS or equal weighting the “top ten” factors.” A key aspect lies in addressing the significant challenge of overfitting when applying ML to noisy financial data. Their ensemble model is a simple average across the ML models and it outperforms both, the single models and when trying to select the best models based on past performance".
Azvedo, Kaiser and Mueller (2023): Global stocks are predicted with 240 firm characteristics. The investigated machine learning algorithms including Gradient Boosting Machine, Random Forest, and Neural Network. A total of 40 models are combined into a model ensemble using simple average. These “composite predictors based on machine learning have long-short portfolio returns that remain significant even with transaction costs up to 300 basis points”.
Cakici Fieberg Metko and Zaremba (2023): Machine learning is applied to forecast stock returns in 46 international markets using 148 firm characteristics. The article describes an ensemble model that combines the outputs of ten individual ML models by taking their average. The authors conclude that “All individual models generate substantial economic gains; however, combining them proves particularly effective”.
Further research confirming the benefits of model ensembles can be found in the literature.
Vontobel
Over the past years, we have also carried out extensive experiments with ensemble methods at Vontobel. Among the different techniques, Boosting — and in particular Gradient Boosted Trees — has consistently delivered strong performance in stock return forecasting. These models stand out for their ability to capture complex, non-linear relationships in noisy financial data while remaining relatively efficient to train and comparatively easy to interpret. At Vontobel, we have already deployed multiple ensemble models in production, where they play a supporting or leading role in shaping portfolio decisions within selected live funds.
Final Thoughts
Across this two-part series, we have seen both the why and the how of model ensembles. From their strong theoretical foundations in classic forecasting literature to their practical construction and successful applications in finance, ensembles emerge as a powerful way to improve predictive accuracy and robustness.
That said, ensembles are not a silver bullet. They come with trade-offs: higher computational costs, reduced interpretability, and the risk of overfitting if applied without care. The key is to strike a balance—leveraging diversity across models to capture more information, while keeping ensemble design simple and grounded in sound principles.
As machine learning continues to evolve, we believe ensembles will remain a cornerstone of predictive modeling, not just in finance but across many data-driven fields. They tend to provide more robust predictions, reduce bias, and help manage uncertainty—key advantages in dynamic and complex environments like financial markets. By combining theory with practice, we are better equipped to use them wisely—making our forecasts not only smarter, but also more resilient
References
Azvedo, V., Kaiser, G.S. and Mueller, S. (2023). Stock Market Anomalies and Machine Learning Across the Globe 24, 419-441. https://doi.org/10.1057/s41260-023-00318-z
Cakici, N., Fieberg, C., Metko, D., and Zaremba, A. (2023). Machine learning goes global: Cross-sectional return predictability in international stock markets, Journal of Economic Dynamics and Control 155, 104725, https://doi.org/10.1016/j.jedc.2023.104725
Diebold, F.X. and P. Pauly. Structural Change and the Combination of Forecasts, Journal of Forecasting 6, 21-40, https://doi.org/10.1002/for.3980060103
Clemen R.T. and Winkler R.L. (1986). Combining economic forecasts, Journal of Business and Economic Statistics 4, 39-46, https://doi.org/10.2307/1391385
Palm, F.C. and Zellner, A. (1992). To Combine or not to Combine? Issues of Combining Forecasts, Journal of Forecasting 11, 687-701. https://doi.org/10.1002/for.3980110806
Rasekhschaffe, K. and Jones, R.C. (2019). Machine Learning for Stock Selection, Financial Analysts Journal 75, 70-88, https://doi.org/10.1080/0015198X.2019.1596678
Uppal, R., Garlappi, L., DeMiguel, V. (2009). How Inefficient is the 1/N Asset-Allocation Strategy?, Review of Financial Studies 22, 1915-1953, https://doi.org/10.1093/rfs/hhm075
Important Information: The content is created by a company within the Vontobel Group (“Vontobel”) for institutional clients and is intended for informational and educational purposes only. Views expressed herein are those of the authors and may or may not be shared across Vontobel. Content should not be deemed or relied upon for investment, accounting, legal or tax advice. Past performance is not a reliable indicator of current or future performance. Investing involves risk, including possible loss of principal. Vontobel makes no express or implied representations about the accuracy or completeness of this information, and the reader assumes any risks associated with relying on this information for any purpose. Vontobel neither endorses nor is endorsed by any mentioned sources. Quantitative inputs and models use historical company, economic and/or industry data to evaluate prospective investments or to generate forecasts. These inputs could result in incorrect assessments of the specific portfolio characteristics or in ineffective adjustments to the portfolio’s exposures. As market dynamics shift over time, a previously successful input or model may become outdated and result in losses. Inputs or models may be flawed or not work as anticipated and may cause the portfolio to underperform other portfolios with similar objectives and strategies. The AI models deployed are predictive by design, which inherently involves certain risks. There are potential risks associated with AI tools as these tools, being relatively new, may harbor undetected errors or security vulnerabilities that may only surface after extensive use. The AI investment strategies are proprietary, as such, a client may not be able to fully determine or investigate the details of such methods or whether they are being followed.

